A basic and quick approach to analyse phishing documents to identify indicators of maliciousness. Refer Part-1 to understand the tools and approach to analyse office word document. This post covers the static analysis of pdf document to identify suspicious objects. (FYI running pdf in sandbox environment can give much insight related to indicators of compromise.) FYI this post doesn't cover complete & in depth analysis (like dealing with malicious obfuscated javascripts or shellcode) of malicious documents
Tools
Analysis
All document samples are pulled from Hybrid Analysis - a free malware analysis service for the community that detects and analyzes unknown threats using a unique Hybrid Analysis technology.
To analyse PDF files, open them in a hex editor and look for the signs of malicious
PDF files, like automatic actions, the presence of JavaScript or Flash, vulnerable encodings etc.
/Page gives an indication of the number of pages in the PDF document. Most malicious PDF document have only one page
/JS and /JavaScript and /RichMedia indicate that the PDF document contains JavaScript respectively Flash. Most malicious PDF documents found in the wild contain JavaScript (to exploit a JavaScript vulnerability and/or to execute a heap spray). Of course, you can also find JavaScript in PDF documents without malicious intend. For example, government agencies are known to provides forms in PDF format with JavaScript to validate input
AA, /OpenAction and /AcroForm indicate an automatic action to be performed when the page/document is viewed. This is often used to execute JavaScript without user interaction
pdfid.py scan a PDF file to look for certain PDF keywords to identify PDF documents that contain (for example) JavaScript or execute an action when opened.The presence or absence of
these keywords will help you to decide if a PDF file is potentially malicious and requires further analysis, or if it is benign and requires no analysis. The keywords PDFiD looks for are
obj
• endobj
• stream
• endstream
• xref
• trailer
• startxref
• /Page
• /Encrypt
• /ObjStm
• /JS
• /JavaScript
• /AA
• /OpenAction
• /AcroForm
• /JBIG2Decode
• /RichMedia
• /Colors with a value larger than 2^24
pdfid.py will not look inside the compressed data of stream objects. You will need other tools to do this. The main purpose of pdfid.py is to aid you with deciding if a PDF file requires further analysis or not (especially if it comes from an untrusted source)
Check the file properties and integrity of pdf sample

Run pdfid.py to identify suspicious indirect objects
identified a /JS /JavaScript and an /EmbddedFile along with an /OpenAction which means an action will be performed once the pdf is opened

Run pdf-parser.py to search for javascript indirect object

It was found that doc dew008.docx will be launched once pdf is opened (the other indirect objects are analysed). pdf-parser.py can do lot of good stuff here, but peepdf.py is preferred here to show and extract streams in native format.

It's an interactive tool to deal with individual indirect objects/streams and also can dump streams by directing the output.

peepdf.py can also check the reputation of pdf file in virustotal, it can give an initial glance about the nature of file. Interactive mode can be selected with -i option to look,decode and analyse streams

Help option in interactive mode with documented commands

object <object_number> can give information about object

Observe the stream 5 and stream 8 (it's already found through peepdf.py output that object 8 and object 5 has streams). The file header PK for stream 8 was found to be office word document

stream 8 is dumped and checked the metadata and file properties using file command. The hash value can be checked in VT or run doc in a sandbox environment to get more insights but, this analysis is all about analyzing document without running in any sandbox

The dumped word file is unzipped to see for any external relationships with type oleobject which is an rtf file

Wow! wget it and analyse
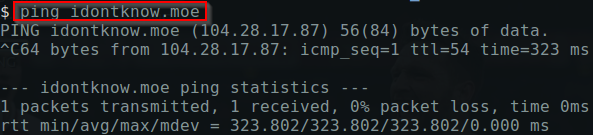
It was up luckily :)

ptceg.doc was downloaded and checked with file properties

Cool ! found to be RTF ! CVE 2017-11882 ?? lets run rtfobj

Probably CVE-2018-0802 which superseded CVE-2017-11882
Further analysis need to be done !
IOCs
93fc24573bd563f08b3a6a71276bfe
98341b7c83f0f3b1e4ca16d6599c71
2ce1f20a6909cfa1722ef3d5e4302f
hxxps://idontknow[.]moe/files/
98341b7c83f0f3b1e4ca16d6599c71
2ce1f20a6909cfa1722ef3d5e4302f
hxxps://idontknow[.]moe/files/
6256dead623ef48c9506e9d5dd9222
0ddf7e87957932650679c99ff2e238
13ce56581c8ad851fc44ad6c678982
hxxps://pomf.pyonpyon[.]moe/
Very Nice Write-up Donny!
ReplyDeleteI eenjoyed reading your post
ReplyDelete